6.2. Frequency Analysis#
Frequency analysis is an important part of cryptanalysis. It can be used to crack many of the classical ciphers previously covered in this textbook.
In this section, you will:
learn the relative frequency of each character in the English language
create bar charts using the
matplotlibpackagecrack a ciphertext created with the Caesar cipher
You will not learn to:
efficiently crack ciphertext created with the affine cipher
You should already know how to:
encrypt and decrypt messages using the Caesar and affine cipher
load a plaintext file as a string
use the
str.count()method to count occurrences of substrings in a plaintext or ciphertext messagecreate
listobjects and append data to themimportPython packagesuse the
text_cleanfunction to remove unwanted characters from strings
English letter frequency#
The English language has a predictable distribution of letters. Certain letters consistently appear more often than others.
If you were to:
select an English-language book at random
count the number of occurrences for each English character, A-Z
compute the percentage of characters in the book comprised of each English character
you would obtain approximately the same percentages regardless of the selected book.
Wikipedia provides the individual letter frequencies, shown in the table below.
| Letter | Wikipedia |
|---|---|
| A | 8.167% |
| B | 1.492% |
| C | 2.782% |
| D | 4.253% |
| E | 12.702% |
| F | 2.228% |
| G | 2.015% |
| H | 6.094% |
| I | 6.966% |
| J | 0.153% |
| K | 0.772% |
| L | 4.025% |
| M | 2.406% |
| N | 6.749% |
| O | 7.507% |
| P | 1.929% |
| Q | 0.095% |
| R | 5.987% |
| S | 6.327% |
| T | 9.056% |
| U | 2.758% |
| V | 0.978% |
| W | 2.360% |
| X | 0.150% |
| Y | 1.974% |
| Z | 0.074% |
Computing letter frequencies#
The Wikipedia data lacks a proper citation for the value in the table. You can verify the numbers are reasonable by computing letter frequencies for text contained in the book Pride and Prejudice, by Jane Austen.
Download the plaintext version of Pride and Prejudice. This book is in the public domain and available at the Project Gutenberg website.
Load the plaintext file, clean it using the
text_cleanfunction, and save the result to the stringtext. The output should only contain uppercase versions of the 26 English letters.
with open('pride-and-prejudice.txt', encoding="utf8") as f:
text = text_clean(f.read())
Count the number of times each character appears in
text. Then compute the percentage of the entire book comprised of each letter.
LETTERS = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
letter_frequencies = []
text_length = len(text)
for char in LETTERS:
letter_frequencies.append(100*text.count(char)/text_length)
letter_frequencies
[7.738792200306681,
1.6968936804213777,
2.5491468405731954,
4.140551082626144,
12.905055880401802,
2.244641245282882,
1.893009784054782,
6.268465183047739,
7.0592734641499035,
0.17581573061405004,
0.6057486306310879,
4.000261004795963,
2.7414566242654708,
7.019035224772256,
7.499900310668209,
1.5738226689915427,
0.11563962487810714,
6.066548972837376,
6.139050305049356,
8.72916039832232,
2.811057903188971,
1.0585194502948991,
2.2788981247530424,
0.15714663756946534,
2.3620934034662886,
0.1700156240370917]
The percentages are shown alongside the values provided by Wikipedia in the table below:
| Letter | Wikipedia | Pride and Prejudice |
|---|---|---|
| A | 8.167% | 7.739% |
| B | 1.492% | 1.697% |
| C | 2.782% | 2.549% |
| D | 4.253% | 4.141% |
| E | 12.702% | 12.905% |
| F | 2.228% | 2.245% |
| G | 2.015% | 1.893% |
| H | 6.094% | 6.268% |
| I | 6.966% | 7.059% |
| J | 0.153% | 0.176% |
| K | 0.772% | 0.606% |
| L | 4.025% | 4.000% |
| M | 2.406% | 2.741% |
| N | 6.749% | 7.019% |
| O | 7.507% | 7.500% |
| P | 1.929% | 1.574% |
| Q | 0.095% | 0.116% |
| R | 5.987% | 6.067% |
| S | 6.327% | 6.139% |
| T | 9.056% | 8.729% |
| U | 2.758% | 2.811% |
| V | 0.978% | 1.059% |
| W | 2.360% | 2.279% |
| X | 0.150% | 0.157% |
| Y | 1.974% | 2.362% |
| Z | 0.074% | 0.170% |
The values provided from Wikipedia are very close to the values produced by analyzing Pride and Prejudice. Some values are within 0.01 of each other. The results of this analysis indicate it is reasonable to use the values provided by Wikipedia, even though they do not match perfectly with Pride and Prejudice.
Analyzing only a single text often leads to slight deviations from the average values provided by Wikipedia. Letter frequency will naturally differ by author and subject. However, combining multiple lengthy texts will likely demonstrate a letter frequency distribution similar to the values found in the Wikipedia article.
Visualization in Python#
Numerical data is difficult to analyze when formatted as a list. A data visualization will reveal patterns and trends in the data. The summary data stored to the list letter_frequencies is categorical; a bar chart is the most appropriate way to visualize the categorical data it represents.
Python has several data visualization packages, including: Matplotlib, Seaborn, Altair, Bokeh, Plotly, and more. This course will use Matplotlib.
Creating bar charts#
To create a bar chart of the data stored in letter_frequencies:
Import the Matplotlib library. Most installations of Python include this package by default. If not, visit Matplotlib to learn how to install it.
import matplotlib.pyplot as plt
Construct a bar chart by calling
plt.bar().plt.bar()accepts two list arguments: the first contains the labels for the categorical data, the second contains the numerical data that represents the height of the bars.
plt.bar(list(LETTERS), letter_frequencies)
Configure the labels on the bar chart. Matplotlib allows you to customize almost every aspect of the chart, including the x-axis label, y-axis label, and chart title.
plt.xlabel('Letters')
plt.ylabel('Frequency')
plt.title('Frequency Analysis')
Show the chart. The previous commands have generated the chart and configured the chart, but have not yet displayed it. Combine the earlier commands with
plt.show()to display the customized bar chart.
plt.bar(list(LETTERS), letter_frequencies)
plt.xlabel('Letters')
plt.ylabel('Frequency')
plt.title('Frequency Analysis')
plt.show()
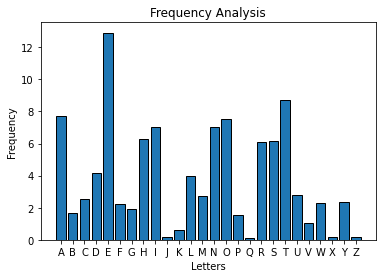
Analyzing a bar chart#
The bar chart displays the following characteristics:
A and E are both high frequency letters spaced 4 apart from each other
H and I are relatively high frequency letters adjacent to each other
N and O are relatively high frequency letters adjacent to each other
R, S, and T are relatively high frequency letters adjacent to each other
Most other letters have relatively low frequency, some with very low frequency
Together these traits form a “fingerprint” for the English language. The distribution has predictable peaks and valleys. Because the Caesar cipher creates ciphertext characters by shifting each individual plaintext letter by the same number of positions, the ciphertext bar chart will have the same peaks and valleys. However, the position of the peaks and valleys will be shifted by an amount equivalent to the key-value.
For example, consider the following ciphertext created with the Caesar cipher and corresponding frequency distribution:
PMOLO HKHUF AOPUN JVUMP KLUAP HSAVZ HFOLD YVALP APUJP WOLYA OHAPZ IFZVJ OHUNP UNAOL VYKLY VMAOL SLAAL YZVMA OLHSW OHILA AOHAU VAHDV YKJVB SKILT HKLVB A
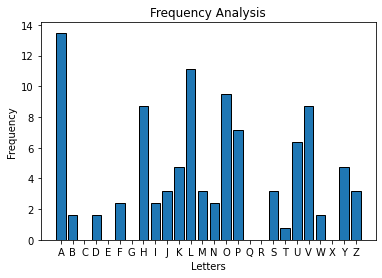
Even with this fairly short piece of ciphertext, you can observe the peaks and valleys present in the plaintext:
H and L in the ciphertext likely correspond to A and E in the plaintext
O and P in the ciphertext correspond to H and I in the plaintext
U and V in the ciphertext correspond to N and O in the plaintext
Y, Z, and A in the ciphertext correspond to, R, S, and T in the plaintext
If you assume that the ciphertext letter L corresponds to the plaintext letter e then you can determine the key used in the Caesar cipher. Since L has a position of 11 in the alphabet and e has a position of 4, the difference in their positional values is 7. This value is equivalent to the key.
This example made a guess about the ciphertext letter than corresponded to the plaintext letter e. This could have just as easily been completed using a guess regarding which ciphertext letter corresponded to any other the plaintext character. a and e are frequent choices because they are easiest to identify in the bar chart.
Applying the key of 7 to the ciphertext yields the following plaintext:
If he had anything confidential to say, he wrote it in cipher, that is, by so changing the order of the letters of the alphabet, that not a word could be made out.
Life of Julius Caesar 56 by Suetonius
Exercise for the Reader
Write a function character_frequency that:
takes in a string of text
cleans the string using the
text_cleanfunctionreturns a list of 26 frequencies in order from A to Z
Frequency analysis for the affine cipher#
Frequency analysis on ciphertext generated with the affine cipher requires additional consideration. The order of the plaintext alphabet is not preserved in the ciphertext alphabet. As a result, you can’t search for the the peaks that correspond to the A/E, H/I, N/O, R/S/T plaintext groupings.
For example, consider this ciphertext generated with an affine cipher:
KRETI JUKRP TUCHI GRDPT UHUJK XUDET IVVKP RIPER EYPWD KHPWO UPTIJ ULKJJ UDOKP TPTUU RDYIL OIHAY ERDER IINWY AUJJR IHWUP EDHWV EHUYE RDWTI JUOKP TRIPT KRCKR KPPIY KPDIO RIRIH PIUEP KPOEY ETIVV KPTIJ UERDP TEPAU ERYMI ALIHP KPTED EZUHL UMPJW HIGRD DIIHJ KSUEZ IHPTI JUZEK RPUDC HUURO KPTEY TKRWW UJJIO VHEYY SRIVK RPTUU FEMPA KDDJU PTUDI IHIZU RUDIR PIEPG VUYTE ZUDTE JJJKS UEPGR RUJEX UHWMI ALIHP EVJUP GRRUJ OKPTI GPYAI SUOKP TZERU JJUDO EJJYE RDLJI IHYPK JUDER DMEHZ UPUDZ HIXKD UDOKP TZIJK YTUDM TEKHY ERDJI PYERD JIPYI LZUCY LIHTE PYERD MIEPY PTUTI VVKPO EYLIR DILXK YKPIH YPTUP GRRUJ OIGRD IRERD IRCIK RCLEK HJWVG PRIPQ GKPUY PHEKC TPKRP IPTUY KDUIL PTUTK JJPTU TKJJE YEJJP TUZUI ZJULI HAERW AKJUY HIGRD MEJJU DKPER DAERW JKPPJ UHIGR DDIIH YIZUR UDIGP ILKPL KHYPI RIRUY KDUER DPTUR IRERI PTUHR ICIKR CGZYP EKHYL IHPTU TIVVK PVUDH IIAYV EPTHI IAYMU JJEHY ZERPH KUYJI PYILP TUYUO EHDHI VUYTU TEDOT IJUHI IAYDU XIPUD PIMJI PTUYS KPMTU RYDKR KRCHI IAYEJ JOUHU IRPTU YEAUL JIIHE RDKRD UUDIR PTUYE AUZEY YECUP TUVUY PHIIA YOUHU EJJIR PTUJU LPTER DYKDU CIKRC KRLIH PTUYU OUHUP TUIRJ WIRUY PITEX UOKRD IOYDU UZYUP HIGRD OKRDI OYJII SKRCI XUHTK YCEHD URERD AUEDI OYVUW IRDYJ IZKRC DIORP IPTUH KXUH
The bar chart that corresponds to the ciphertext is shown below:
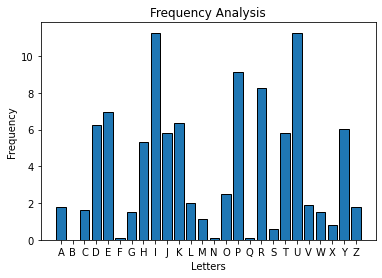
The above bar chart does not demonstrate any of the patterns that were present when the ciphertext was generated with a Caesar cipher. It doesn’t share a fingerprint with the English language as seen previously.
Instead, create a bar chart with bars ordered from left to right in decreasing frequency. This type of bar chart will allow you to make easy correspondences between the most frequent ciphertext letters and the most frequent plaintext letters. These correspondences are the most likely mappings between the two alphabets.
The distributions vary slightly but have a similar shape. The bar charts indicate that the ciphertext letters I and U are the most frequent letters, and likely correspond to the letters E and T. If you were to assume corresponding letters in the bar charts reveal the true mapping, and that (\(\text{I} \rightarrow \text{e}\), \(\text{U} \rightarrow \text{t}\), etc.), deciphering the message yields the following:
stiuenlstguloyectjgulylnsfljiuexxsgtegitiwgajsygarlguenlhsnnljrsgugulltjwehreypwitjite ekawplnnteyalgijyaxiylwitjauenlrsgutegustostsggewsgjerteteygeligsgriwiuexxsguenlitjgui gplitwvepheygsguijiblyhlvgnayectjjeeynsdlibeyguenlbistgljoylltrsguiwustaalnnerxyiwwdte xstgullzivgpsjjnlguljeeyebltljetgeigcxlwuibljuinnnsdligcttlniflyavepheygixnlgcttlnrsgu ecgwpedlrsgubitlnnljrinnwitjhneeywgsnljitjviyblgljbyefsjljrsgubenswuljvuisywitjnegwitj negwehblowheyuigwitjveigwguluexxsgriwhetjehfswsgeywgulgcttlnrectjetitjetoestohisynaxcg tegqcsglwgyisougstgegulwsjlehgulusnngulusnniwinngulblebnlheypitapsnlwyectjvinnljsgitjp itansggnlyectjjeeywebltljecgehsghsywgetetlwsjlitjgultetitegulyteoestocbwgisywheyguluex xsgxljyeepwxiguyeepwvlnniywbitgyslwnegwehgulwlriyjyexlwuluijruenlyeepwjlfegljgevnegulw dsgvultwjststoyeepwinnrlyletgulwiplhneeyitjstjlljetgulwiplbiwwiolgulxlwgyeepwrlylinnet gulnlhguitjwsjloestostheygulwlrlylguletnaetlwgeuiflrstjerwjllbwlgyectjrstjerwneedstoef lyuswoiyjltitjplijerwxlaetjwnebstojertgegulysfly
This text is not English. In fact, it does not appear to be a coherent message at all.
Warning
Sorted frequencies are sensitive to errors. If a letter is under- or over-represented in the plaintext message, it will also be under- or over-represented in the ciphertext. When the bars are arranged by frequency this error will impact nearly all the correspondences between the ciphertext and expected English bar charts. This will lead to numerous incorrect mappings between the alphabets.
For example, this message used the plaintext character l less than usual. The encryption process mapped the plaintext letter l to the ciphertext letter J. Therefore, the ciphertext letter J inherits the same lower than expected frequency. As a result, the bar for J will appear lower in the ciphertext distribution than it would have if the plaintext letter l had been used normally. Comparing corresponding bar positions creates an incorrect mapping between the ciphertext letter J and the plaintext letter d. This causes a chain reaction which alters the order of subsequent bars, resulting in numerous incorrect mappings between the alphabets.
The actual plaintext message is:
In a hole in the ground there lived a hobbit. Not a nasty, dirty, wet hole, filled with the ends of worms and an oozy smell, nor yet a dry, bare, sandy hole with nothing in it to sit down on or to eat: it was a hobbit-hole, and that means comfort. It had a perfectly round door like a porthole, painted green, with a shiny yellow brass knob in the exact middle. The door opened on to a tube-shaped hall like a tunnel: a very comfortable tunnel without smoke, with panelled walls, and floors tiled and carpeted, provided with polished chairs, and lots and lots of pegs for hats and coats - the hobbit was fond of visitors. The tunnel wound on and on, going fairly but not quite straight into the side of the hill - The Hill, as all the people for many miles round called it - and many little round doors opened out of it, first on one side and then on another. No going upstairs for the hobbit: bedrooms, bathrooms, cellars, pantries (lots of these), wardrobes (he had whole rooms devoted to clothes), kitchens, dining-rooms, all were on the same floor, and indeed on the same passage. The best rooms were all on the left-hand side (going in), for these were the only ones to have windows, deep-set round windows looking over his garden and meadows beyond, sloping down to the river.